



Get a personalized demo of Stuut and see how it can help with AR automation.
Every engineer at Stuut can spin up a full copy of production and start working against it in seconds.
That changes how we debug and ship. A customer reports an issue with weird invoice numbers, a slow collections query, or an integration edge case, and the engineer can reproduce it against realistic data immediately. The branch has production row counts, production skew, and the messy long tail that seed scripts usually miss.
Engineers can test migrations against real table sizes, validate background jobs against real customer distribution, and inspect edge cases without asking for production access or fighting over a shared staging database.
The database branch has to be safe before an engineer uses it. Production contains customer PII, live API keys, OAuth tokens, webhook secrets, client certificates for ERP and CRM integrations, password hashes, and TOTP secrets.
Every night, we copy production and mask every sensitive column with NULL or realistic fake data before publishing the database for development.
The masking rules live in masking_rules.json. That file can drift from the schema because adding a column and adding a masking rule are separate edits. An engineer can ship a new integration column like client_secret, merge the schema change, and miss the masking rule. One missed rule can put a real production credential into every engineer’s local database.
The schema already identifies sensitive fields in code. Our SQLAlchemy models use ColumnVisibility.MASKED and ColumnVisibility.PRIVATE to control what appears in API responses. Those labels already determine whether a field appears for a customer, an internal user, or a superuser.
We use those same labels as the source of truth for our masking rules. A column marked MASKED or PRIVATE must have a matching rule in masking_rules.json.
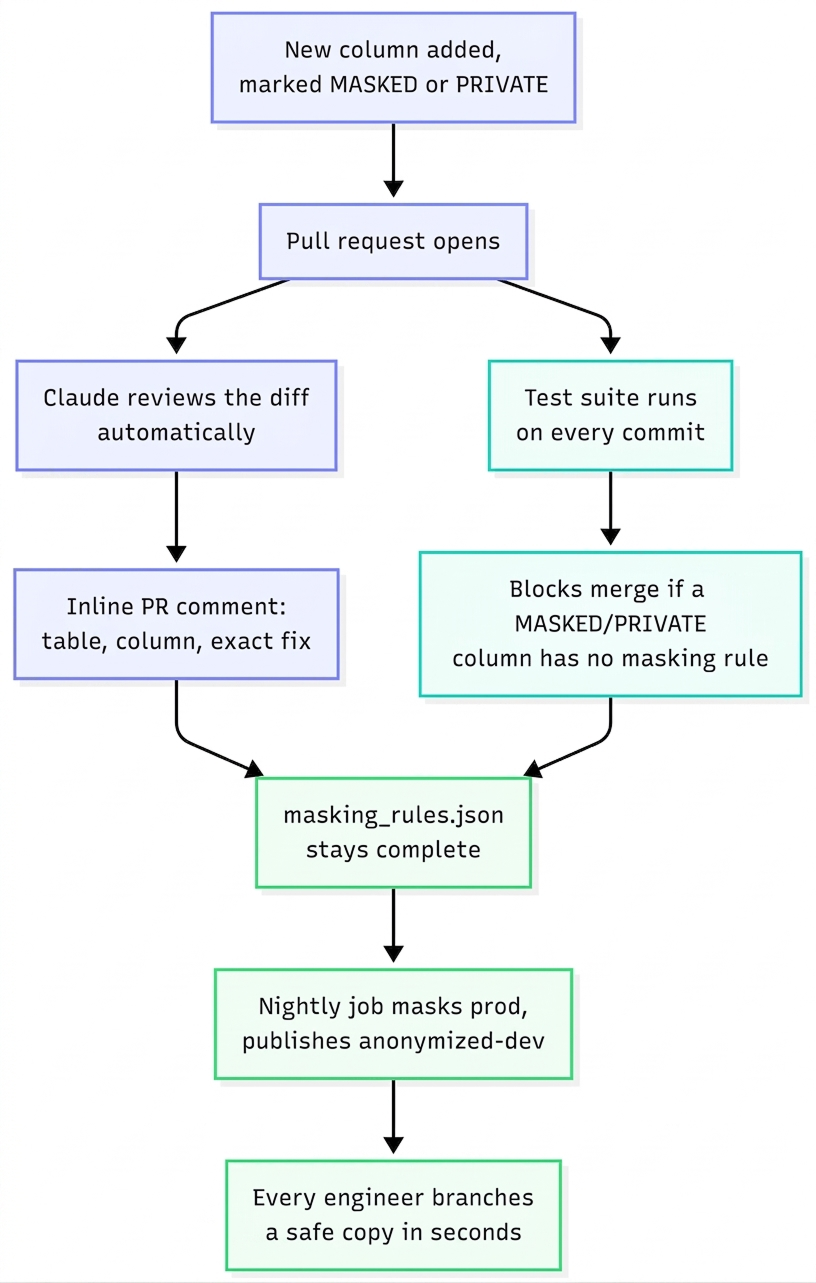
A test in our schema suite walks every SQLAlchemy model and checks that every MASKED or PRIVATE column has a matching entry in masking_rules.json.
It also checks the other direction. Every rule has to point at a column that still exists, so if someone renames or deletes a column, the old masking rule cannot quietly stick around.
There are two exceptions today. Both are bcrypt password hashes, both are irreversible by construction, and each has a one-line comment explaining why it is safe to skip. Anything else marked MASKED or PRIVATE needs a masking rule before the change can land.
Our AI code reviewer checks every pull request against our main branch. When a diff adds a MASKED or PRIVATE label to a model, it leaves an inline comment with the table, column, and the exact masking_rules.json entry that needs to be added.
A typical comment looks like this:
IntegrationConnection.client_secret is marked PRIVATE, but masking_rules.json has no rule for integration_connections.client_secret.That gives the author the exact file and column to fix while the PR is still fresh in their head. The test suite is still the final safety net, but the AI reviewer catches the issue earlier, when it is easier to fix.
It has already caught real integration changes where a new credential column did not have a masking rule. In some cases, it noticed the issue even before the column had been marked MASKED. Similar credential fields on other integrations were already labeled and masked, so the reviewer called out the mismatch. The fix landed in the same pull request that introduced the column.
The AI reviewer and schema test both look across every model in the codebase, but they help in different ways.
The AI reviewer is good at spotting likely mistakes. It can use the surrounding code, the integration being changed, and patterns from similar fields elsewhere in the codebase.
The schema test is simpler and stricter. If a column is marked MASKED or PRIVATE, it needs a masking rule. If it does not have one, the PR cannot be merged.
That matters because review instructions can drift. We might tune the AI reviewer over time. It might get more or less aggressive. The test keeps the core rule in place no matter what.
The same masking pipeline now feeds our preview environments, so a pull request can be reviewed against a live app backed by realistic, anonymized data. In a future post, we’ll show how every PR gets its own safe app and database preview.
The result is a development loop backed by production row counts, production skew, and masked secrets. Engineers can debug against realistic data in seconds. Pull requests get early feedback on likely masking gaps. And the schema test makes sure sensitive fields are not missed before changes land.
If you’re interested to build infrastructure like this, we’re hiring!



